We tend to talk about products as if they were objects: designed, assembled, and delivered. Architecture, processes, and documentation reinforce this view. If the structure looks correct, we assume the result will be correct too.
Hai grandi sogni, vuoi scappare da qui. Sei stanca di restare chiusa in quell’appartamento, senza soldi e senza sapere da dove cominciare. Lo so, la vita costa cara e non è facile.
E intanto il tempo passa: un altro compleanno, un altro anno sulle spalle. Ma ti dico: respira, rimettiti in piedi, non mollare.
Perché anche quando ti senti giù, hai sempre brillato. Non sei mai stata una qualunque, sei sempre stata una stella, piena di vita.
Lo so che questa città è fatta di cuori spezzati e che sembra non esserci via d’uscita. Ma tu puoi farcela: raccogli le forze e vattene da qui, inseguendo i tuoi sogni.
Non dimenticarlo: dentro di te c’è ancora quella luce che non si è mai spenta.
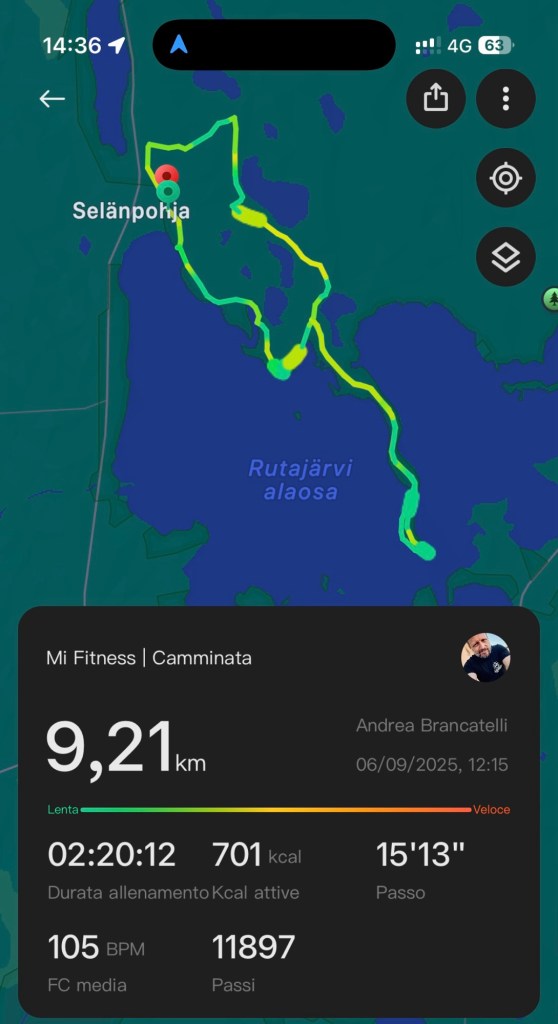
Oggi ho fatto una gita al Leivonmäki National Park, che si trova circa 200 km a nord di Helsinki. Era la prima volta che facevo un’escursione in uno dei famosi Parchi Nazionali della Finlandia e non sapevo bene cosa aspettarmi.
Ad aumentare la confusione ci si è messo il meteo: questa mattina al mio risveglio c’era una nebbia fittissima e non si vedeva a 50 metri dal proprio naso. Ho comunque messo nello zaino ciò che mi sembrava avesse senso e sono partito, fiducioso che nelle due ore e mezza necessarie a raggiungere il parco qualcosa sarebbe cambiato.
Quando sono arrivato, la temperatura era di 19 gradi e c’erano molte persone nel parcheggio del parco. Ho cercato di capire come fossero organizzati e, come sempre accade con i finlandesi, questo mi ha confuso ancora di più: c’erano persone in pantaloncini e maglietta a fianco di persone con il maglione di pile ed il giaccone. A mio avviso l’aria era frizzante, quindi ho deciso di lasciare in macchina un po’ di cose e partire per il giro che si è rivelato bellissimo.
Il sentiero costeggia i vari laghi che sono racchiusi nel parco ed ogni chilometro e mezzo circa offre delle casette dove si può cucinare, mangiare ed approfittare dei servizi igienici. Dopo circa mezz’ora ho deciso di deviare dal sentiero che stavo seguendo per recarmi, lungo il sentiero dedicato alle mountain bike, verso la punta di una penisola che si protende stretta e lunga per quasi 2 km all’interno del lago principale.
Anche su questa penisola c’era una tettoia con annesso braciere, delle persone che pranzavano. Proseguendo un po’ più avanti il sentiero è sceso ed ho potuto toccare l’acqua che aveva una temperatura piacevolissima – non a caso poche centinaia di metri più avanti una ragazza aveva montato una sedia da campeggio, un’amaca, e si stava apprestando a fare il bagno.
Mentre tornavo dalla penisola le nuvole si sono definitivamente aperte ed è arrivato uno splendido sole che ha alzato subito la temperatura dell’aria fino a circa 23 gradi… giusto in tempo per accompagnarmi nella seconda metà del giro per tornare verso il parcheggio.
Lungo tutti i sentieri c’erano numerosissimi frutti di bosco e parecchi finlandesi con il secchiello che li raccoglievano (in tutta la Finlandia la raccolta dei prodotti del bosco è libera e garantita per legge), ho trovato anche numerosi funghi, ma visto che erano in bella mostra e nessuno li aveva raccolti, ho qualche dubbio sul fatto che fossero commestibili. Di solito qui raccolgono un fungo giallo con cui fanno zuppe e salse di cui vanno letteralmente matti.
Vi lascio qualche foto.
Canoe a disposizioneUna delle bellissime torbiereVista sul lagoLe zone per cucinareFunghi!Pineta di Pini SilvestriIsoleFoglie e zanzareLa strada nel bosco di piniFungo!La foresta scoscesa nei pressi del lagoIl tragitto finale
On the road to Helsinki!On the road in Pagnacco (Italy)Valbruna (Italy)Prius in Valbruna (Italy)Me on the RoadLunch in Raczki (Poland)!On the road in Raczki (Poland)House in Kèdainiai (Lithuania)Harbour in Tallin (Estonia)Ferry in Tallin (Estonia)
This is the final article on Eugene, the Enterprise Architecture platform we built at Octo Telematics.
Cloud Governance isn’t just about monitoring costs — it’s about understanding them, optimizing them, and making informed decisions. In our latest work on Eugene, we’ve taken Cloud Governance at Octo Telematics to the next level, integrating multi-cloud cost tracking, service attribution, and real-time insights into a unified platform.
How can forecasting help us predict cloud expenses before they happen?
How do we map cloud costs back to software and business value?
How do we handle cost attribution for shared environments like Kubernetes clusters?
These are some of the challenges we addressed, and we’re now working on predictive cost modeling—so that cloud expenses don’t just get tracked, but anticipated before deployment.
In this follow-up to Eugene: A genie in Enterprise Architecture, we explore how Software Lifecycle Management has been enhanced at Octo Telematics by extending Eugene’s core functionalities. This evolution has streamlined our release process, fed valuable data into our Knowledge Radiator, and improved transparency throughout the workflow.
-32 celsius degrees on the Car Dashboard!Road in LaplandAurora Borealis in LaplandAurora Borealis in LaplandOn the road in LaplandMe on the road in LaplandBeautiful frozen lake in LaplandHoly Trinity and St. Tryphon of Pechenga Church in Nellim, LaplandRaindeer Kebab in Ivalo, Lapland (at Lauran Grilli!)Helsingin tuomiokirkkoWinter in EsplanadiWinter in Helsinki
Octo Telematics's Architecture Team felt the urge to define a structured approach to design platforms and infrastructure effectively. We wanted to fill the gap between the business requirements, the software layer, and the physical layer. That led us to design and implement an Enterprise Architecture Tool tailored to our specific needs that we named Eugene.
Dopo tanti anni di utilizzo di FreeBSD, il passaggio ad ambienti Linux mi da sempre una sensazione di rigidità a causa di alcune funzionalità native del sistema operativo che non trovano un equivalente su Linux.
Una di queste è proprio ZFS – il filesystem nato su Solaris e rapidamente adottato da FreeBSD prima ancora che nascesse l’iniziativa OpenZFS finalizzata a rendere il progetto totalmente Open e trasversale alle implementazioni OS-dependant.