




Today, with a great help of my pal Ilario Febi, we kicked-off a new plugin for the marvelous Cheshire Cat AI Framework.
(more…)Cheshire Cat AI is a production-ready AI framework. With few lines of Python code you can build your own custom AI assistant and have it available as a microservice.
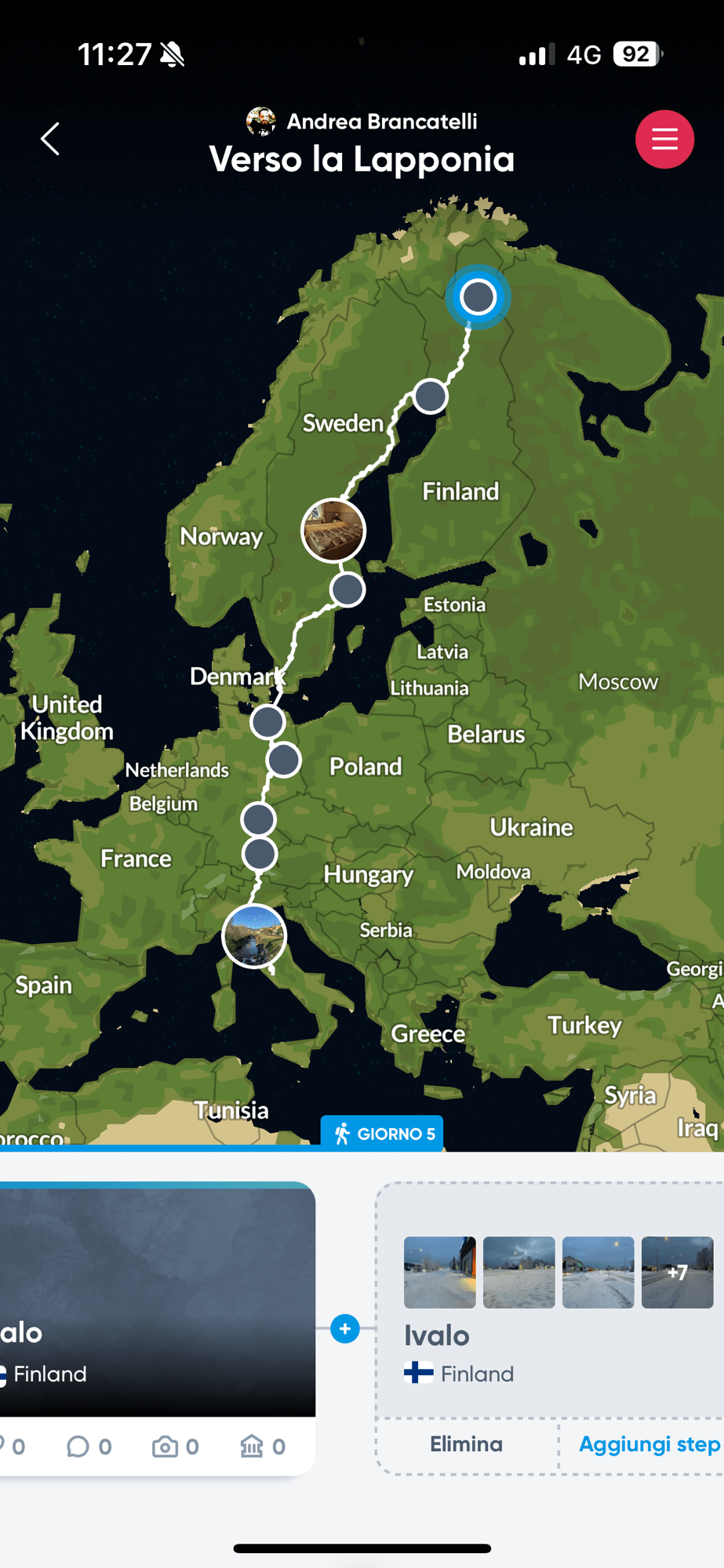
Italy, Germany, Sweden, Finland


































Thou shalt not excessively annoy others. Thou shalt not be too easily annoyed.
Fidonet Policy

From time to time you may find yourself in need of exporting all the topics definition from a Kafka server to recreate them on a new server. Kafka command line tools are pretty handy to do that but I could not find an already cooked script that could both dump Topics definition to a CSV file and then read it back to create topics – so I made my own two scripts.
(more…)Platforms don’t become useful products. Useful products become platforms.
Tony Fadell
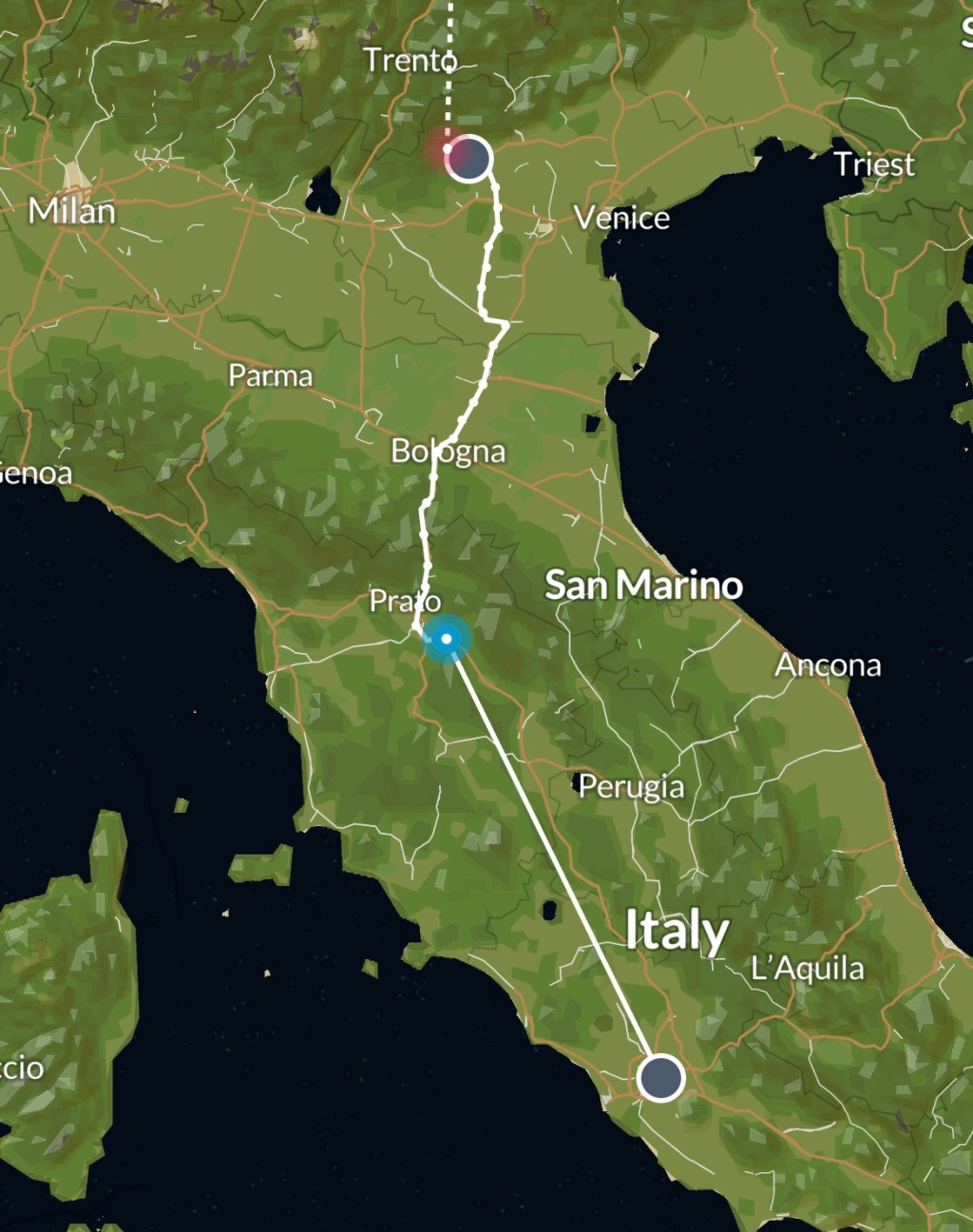
Day 1! Finalmente partiti! Come sempre Roma ha tentato di trattenerci inventandosi qualsiasi tipo di problema, ma abbiamo tenuto duro e per le 11 eravamo sulla strada.
(more…)
Da oramai parecchi anni, il periodo estivo è l’occasione per fare un’abbuffata di città estere. Complice la frequente necessità di andare in vacanza nelle settimane a cavallo della settimana di Ferragosto – che rende quasi impossibile l’ipotesi di andare in vacanza in un singolo posto senza spendere cifre esorbitanti – il mese di Agosto diventa l’occasione per un bel tour in macchina di varie città europee.
(more…)








